SWE Hiring is Cooked
Agents are superhuman at the “1 hour exercise” format


If anyone tells you they still know how to interview SWEs, I wouldn’t believe them.
At Surge, I recently created a 1 hour coding challenge – the type you might give to an engineering candidate during the hiring process. The exercise needs to be something where everyone comes into it fresh, so the playing field is even. And to make it feasible for candidates, it needs to fit in a short timebox.
One might reasonably ask candidates to forego using agents, but honestly, I’m not sure what the value of that is these days. Ten years ago, the industry collectively decided that “code on your own laptop with the setup you’re comfortable with” was a more meaningful reflection of candidate performance than “code on the whiteboard, oh btw half my markers are dead, sorry”. Telling a candidate not to use AI today would be similar to asking them not to use a keyboard.
And honestly, AI-assisted engineering is a different skillset than coding by hand. Some people are better at it than others, and an effective modern hiring process gives a signal on that.
So we need an AI-native coding exercise with a 1-hour timebox. I built a task around this prompt to the human engineering candidate:
Our app, SlopBook, needs to be able to render huge monolithic markdown docs – like 25M tokens. We’re using Marked v18.0.0 with some custom extensions, but it’s having perf issues. Your goal is to make our renderer more performant, but all our existing docs need to render the same way as they do today. Maybe we need to do a WASM rewrite?
The obvious question for any hiring filter: how well does it identify top talent? To put this to the test, I asked a handful of our engineers to try the assignment – and a handful of people who self-identify as deeply non-technical. (I had to reassure them that no one would judge them for their work on this assignment. “It’s the engineers who should be worried about this – think of this like you being invited to do a 1:1 against LeBron – either you get a shocking upset, or no one bats an eye.”)
To give a sense of how non-technical some of these people were, here’s a representative note that someone sent me along with their submission:
I literally have no idea what any of these words mean. The assignment asked me to give you a tarbell [sic] but I don’t know what that is, so Claude made one for me, as well as doing everything else.
I then blind-graded the submissions on the standard S through F tiers. The distribution:
count
S │ 1 █
A │ 5 █████
B │ 3 ███
C │ 5 █████
D │ 3 ███
F │ 3 ███
What happened when I unblinded the results?
Total disaster.
Two of the three engineers got into the A tier. The third was in the D tier, on account of an unlucky choice to go down a bad path initially and being unable to recover within an hour.
The one person in the S tier was the one person who used Opus 4.7 instead of 4.6 or GPT-5.4. (It was released the same week I did this investigation.) When I asked the author about their process, they said “lmao I’m a PM with no technical background.”
I also asked the two non-engineer A tier submissions about their process. One of them said “I did it all in Cowork”, and the other said “I used Claude Code with Sonnet 4.6.” I asked “Why not Opus?” and they responded “oh is that supposed to be better? Who makes that one?”
Le sigh.
I’d also asked a number of semi-technical people to attempt the task. They steered the models more than the non-technical people, but with worse judgment than the engineers. This was purely negative – the A and S tiers were populated exclusively by professional engineers steering the agents, or vibe jockeys giving the agents full autonomy.
Within the cohort of non- and semi-technical people, it seemed like the score was mostly reflecting luck: agents tend to have a tight but real spread on most tasks, and the dominant factor in non-engineer human performance seemed to be which roll of the GPU dice they got.
This was also a humbling experience re: my ability to detect LLM usage. Obviously, all the writing was LLM-driven. It would be a poor use of time for the humans to write the submission writeup by hand. The question was: when were people using AI to amplify, rather than replace, their own thinking? When were they providing an LLM the ideas in an outline, and using it to fill in the prose, vs. fully delegating the critical thinking to it?
Turns out I have no taste for this in this context. In my notes, I wrote in one instance “this feels like a human driving an LLM”, because it was more insightful than the rest of the submissions. Wrong. What I was actually picking up on: this was the one submission that used Opus 4.7.
Why does this happen?
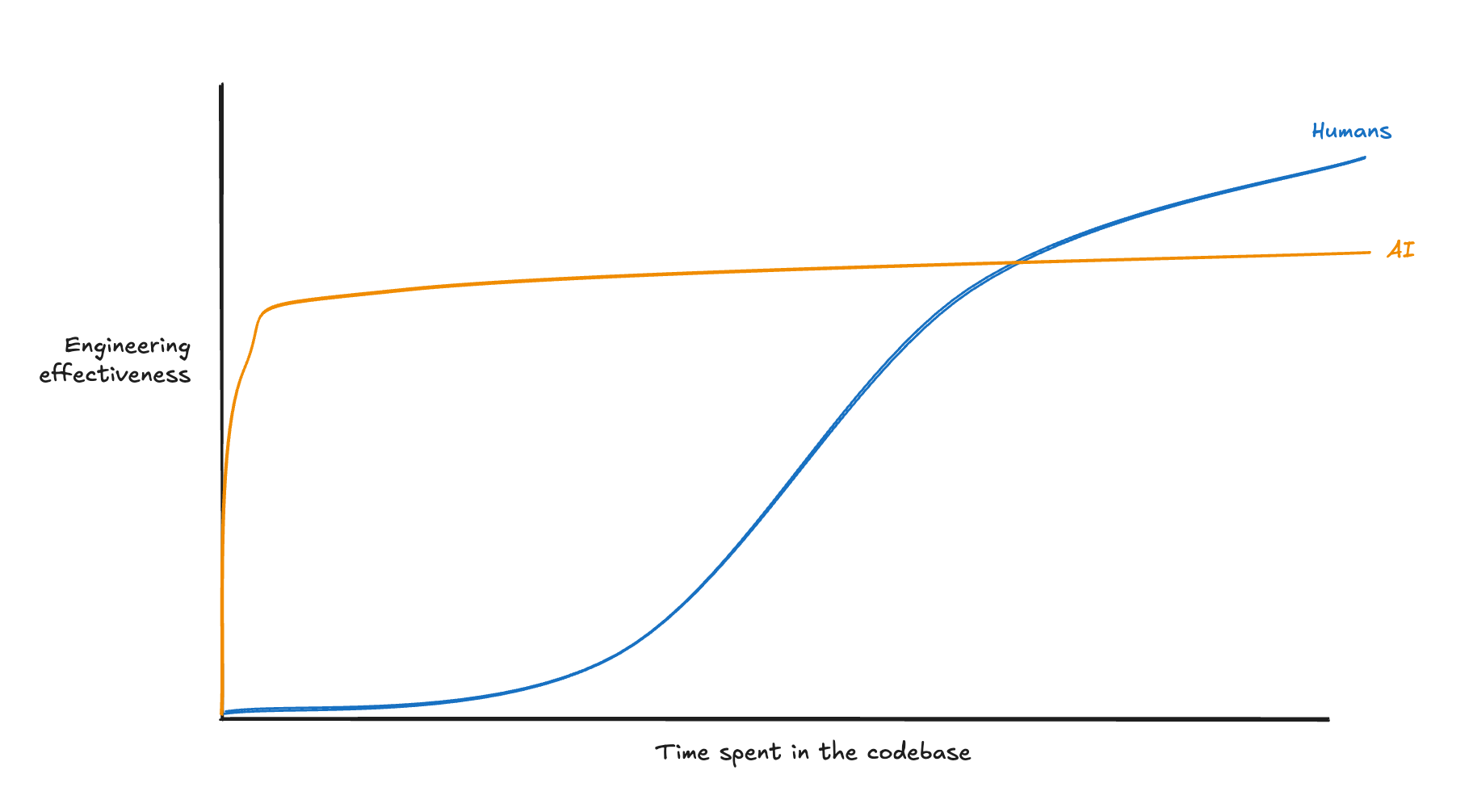
The constraints on this exercise, imposed by the realities of the hiring process, place it squarely in AI’s area of greatest strength relative to humans. AI can quickly scan a codebase in under a minute, and build deeper context in ~15, and quickly be autonomously effective – but then plateau. Humans, by contrast, are close to useless in an unfamiliar codebase, but as they learn, they keep getting better.
The graph above intentionally doesn’t label the x axis, because the intersection of where humans have parity with AI skill will keep moving (and not in our favor).
Where is that intersection today? Based on my results above, I’m certain that AIs are so much better than humans in the first hour of context gathering that humans are of no help. I’m also highly confident that a professional engineer (using agents) would outperform today’s standalone agents after 2 weeks in a real world codebase. I would estimate, then, that today’s crossover point is somewhere around 3 days.
What does this mean for hiring SWEs?
It’s not clear to me that it’s possible to accurately screen software engineers today. The systems design interview is still intact for now, because it’s hard to cheat at, and it’s meaningful whether someone can have a verbal conversation about tech tradeoffs.
I also think you could do something interesting with code review – not finding issues, as agents will outperform at that, but applying judgement as to which issues are important to fix.
But I’m not sure how to assess someone’s ability to use agents in an appropriately-short timebox. I tried another variant of the exercise that was basically “clone Linear, you have one hour, make no mistakes”. But that ended up also feeling not super interesting – the dominant factor in performance will end up being “what elaborate multi-agent swarm orchestration have you set up”, which isn’t that important for daily engineering work on a real codebase.
And the “let’s stand up a new app at absolute lightning speed” task also isn’t super indicative of real work, since it’s rare that you’re starting from a total greenfield and trying to make something huge immediately. There is a fair bit of skill in defining lanes for agents and keeping them from stepping on each others’ toes at breakneck pace, but it’s not a skill you use that often as a SWE.
What does this mean for getting hired as a SWE?
In 2023, there was a possible future where AI stayed in the original Github Copilot autocomplete regime. You, the human, indicate intent by typing the first characters, and the AI fulfills that intent.
That’s not the future we got. Instead, we’re increasingly seeing that AI can autonomously outperform humans end to end at small time scales. And there’s every reason to expect those time scales to increase: as core coding correctness benchmarks begin to saturate, labs will start training on broader SWE skills, like “reasoning about how to rearchitect this codebase to scale to 10x the traffic” or “reading Slack to figure out what needs to be done”.
So near term, people who can reason about “what needs to be done” & have good taste about how to do so will outperform those whose main value is coding more narrowly.
Long term, I expect it all to get washed out.
What does this mean for everyone else?
AI 2027 predicts bigger-than-industrial-revolution impact from AI over the next decade. The turning point (e.g. when AI starts actually moving quickly, relative to today) is the development of the superhuman coder – it kicks off a wave of recursive self-improvements.
Their median forecast is that the superhuman coder will arrive in the next few years.
For a zero-prior-context task in a 1 hour timebox, it’s already here.