Studying French is Hard So Let’s Complain About Agents Instead

I’m studying French so I can be the group translator for my grandmother’s 90th birthday trip to Paris. And what better way to study than by building an AI study app instead of actually grinding vocab?
My French teacher sends me vocab flashcards via Quizlet, but it’s basically just English/French word pairs. I want an LLM to generate contextual usage in a sentence, exercises to prove my understanding, etc. Plus, I have some of my own UI idiosyncratic preferences that Quizlet doesn’t meet.

It’s 2026! Why settle for generic software when we can create something for ourselves?
Setup
I started by wish-dumping on Claude to get it to create a prompt. I also gave it high level architectural guidance. Here’s the final result1:
Build a full-stack TypeScript Next.js app that imports flashcard sets from Quizlet and enhances them with LLM-generated contextual enrichment and interactive exercises. The app is for a single user learning French.
Pages / Views
Word List
Browse all imported words. Each word shows French → English.
Search and filter.
Tap a word to see its detail view.
Word Detail
The word and translation
Enrichment: example sentences, usage note, related forms
Exercises grouped by type
“Generate more exercises” button
Exercise View
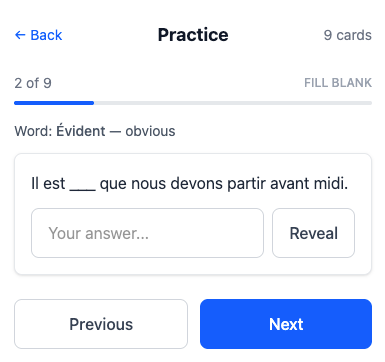
Fill-in-the-blank: Show the sentence with a blank. User types the answer. Tap to reveal correct answer.
Context guessing: Show the French sentence. User thinks about the meaning. Tap to reveal the English meaning and explanation.
Sentence construction: Show the prompt. User types a French sentence. Submit button triggers live evaluation. Feedback displayed below. User can submit another attempt independently.
Keep it clean and simple. No flashy UI. Think “Notion-level simplicity” — readable typography, good whitespace, clear hierarchy. Dark mode is not required but is a nice-to-have.
The flashcard set to ingest is at: <url>. You can hardcode this URL into the app for now.
[... plus plenty more that’s excerpted]
You have one shot to complete this entire task. Do not ask the user follow-up questions or present an unimplemented plan. Just do it!
Spend as long as you need on this to produce amazing results. You do not have a token or time limit.
Next, I created projects/envs/API keys with all the relevant services (Vercel, Trigger.dev, Neon, Anthropic).
Then, I set up a GH repo with the necessary MCPs, prompt in a markdown file, agents.md, etc. Here is the initial state the agents saw.
Finally, I invoked both Claude 4.6 Opus 1M and GPT-5.3-Codex2, in their separate worktrees, with a prompt that simply pointed the agent to the prompt markdown file.
GPT-5.3-Codex
Total failure.
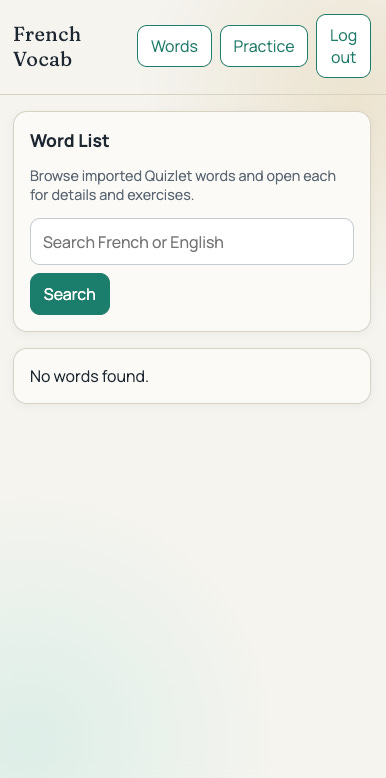
Codex’s agentic output included:
In this environment, Quizlet currently returns Cloudflare challenge/captcha for undocumented endpoints. I added multi-endpoint + HTML fallback parsing and explicit error reporting, but live ingestion may still fail until Quizlet allows requests from the runtime.
This isn’t helpful – without live data, neither us nor Codex can actually test the app to make sure it works.
Codex first tried to curl the web URL for my flashcard set, which was provided in the prompt. This got blocked by Cloudflare, so it then tried a bunch of URL endpoints “from my memory” (which may be a polite way of saying “totally hallucinated”). None of those worked, so it gave up, and reported the app as complete.
On the plus side, Codex continues its trend of producing nicer-looking UIs than Claude. It uses the modern stylish “serif header, sans-serif body text” look, adds a nice gradient, etc.
But even then, there are polish issues: the “log out” button wraps awkwardly on mobile, the vertical rhythm is a bit off, etc.
Grade: D-
Claude Opus 4.6 1M
Less of a total failure!
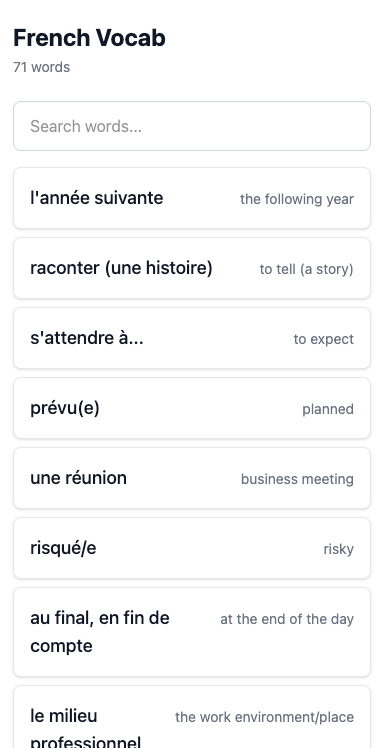
On the plus side, it did successfully extract the flashcard data from Quizlet.
It identified the Cloudflare blocking, so it launched its Playwright browser, read all the flashcard data out of the DOM, and manually uploaded it to the db. In its post-work writeup, it called this out as a known limitation, since it hadn’t met the requirement to do a recurring automatic sync.
(I don’t think there was a way to do this any better, since Cloudflare requires a browser to load the page, and the flash card data is embedded in the initial page HTML. So I think the agent did the perfect thing: do a one-time static import to get something working, then take a follow-up note to think about how to automate this.)
If you click into a specific word:
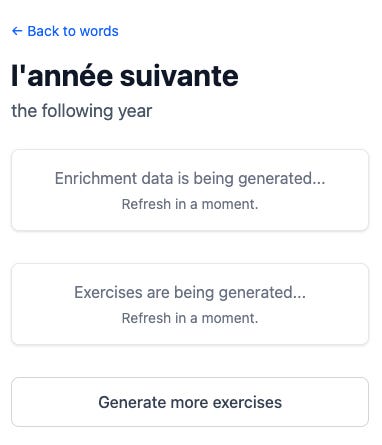
You can refresh in as many moments as you want, but the exercises never load. Clicking “generate more exercises” does not result in more exercises being generated.
There’s also a practice mode, which is neat:
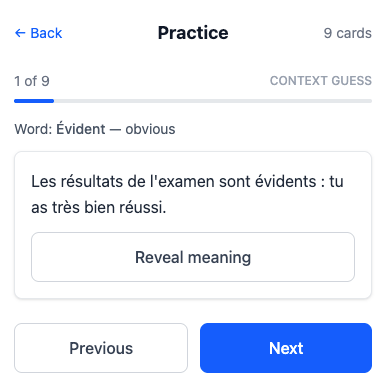
Claude implemented a few different types of exercises:
Given a French sentence, guess what it means in English, then “Reveal meaning” to get the answer. (But why not make me actually write the English translation, then check to see if I got it correct?)
Fill in the blank to use the word in a sentence. (This one is kinda dopey: it’s almost always just verbatim copying the word into the blank, with possibly some gender agreement.)
Use the word in a sentence, then get feedback about whether you did it properly:
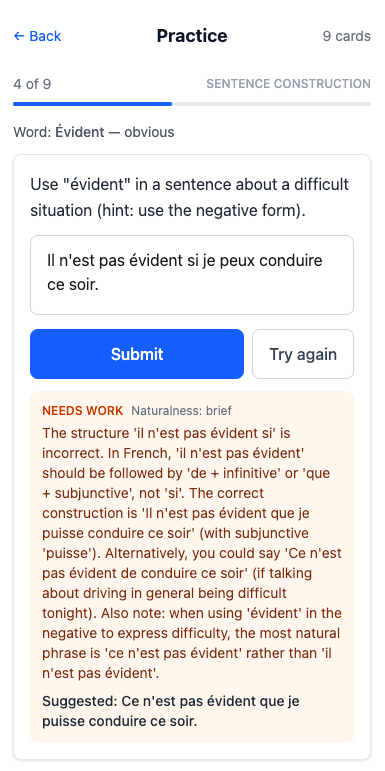
This is really helpful!
It would have been nice if Opus had implemented formatting for the LLM French feedback, rather than dumping it into a single paragraph.
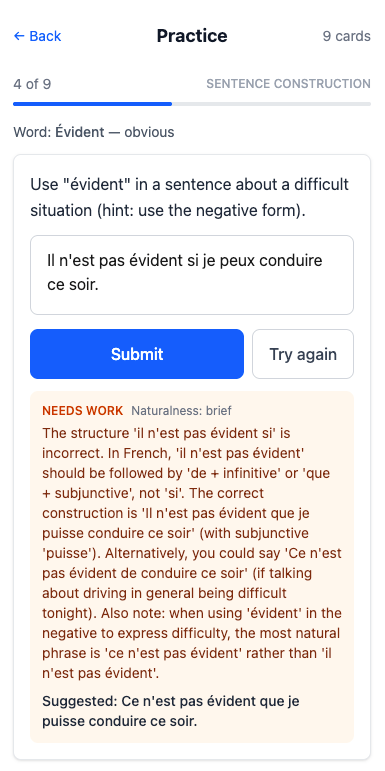
My excitement at this working was quickly dashed as I realized that it only works for a single word. So I’ll be really good at using évident in a sentence and not much else.
Grade: C-
Conclusion
Today’s agents are very powerful on a short leash, but have extremely limited ability to check their own work – which severely limits their autonomy. Both agents produced apps that were fundamentally broken in ways that would have been obvious if they’d done a click-through. Neither added unit tests. Both reported that they were “done” despite having big gaps.
That level of carelessness doesn’t meet the bar for even a junior engineer, so today’s agents aren’t yet drop-in replacements for devs. They’re firmly in the “copilot / powerful tool” category.
That said, I expect core model training and agentic harness advances will dramatically improve this in the coming six months, at which point we’ll see a step-function change in agent effectiveness.
I think this prompt would be better if it led with the “what are we doing here” vs. diving straight into implementation details, but I want to be deferential to how Claude wants to write the prompt to just see how well this whole process goes with a light touch. Besides, models tend to pay most attention to the last thing you say, so maybe it’s actually okay to put it at the end.
Reasoning effort: “Extra High”